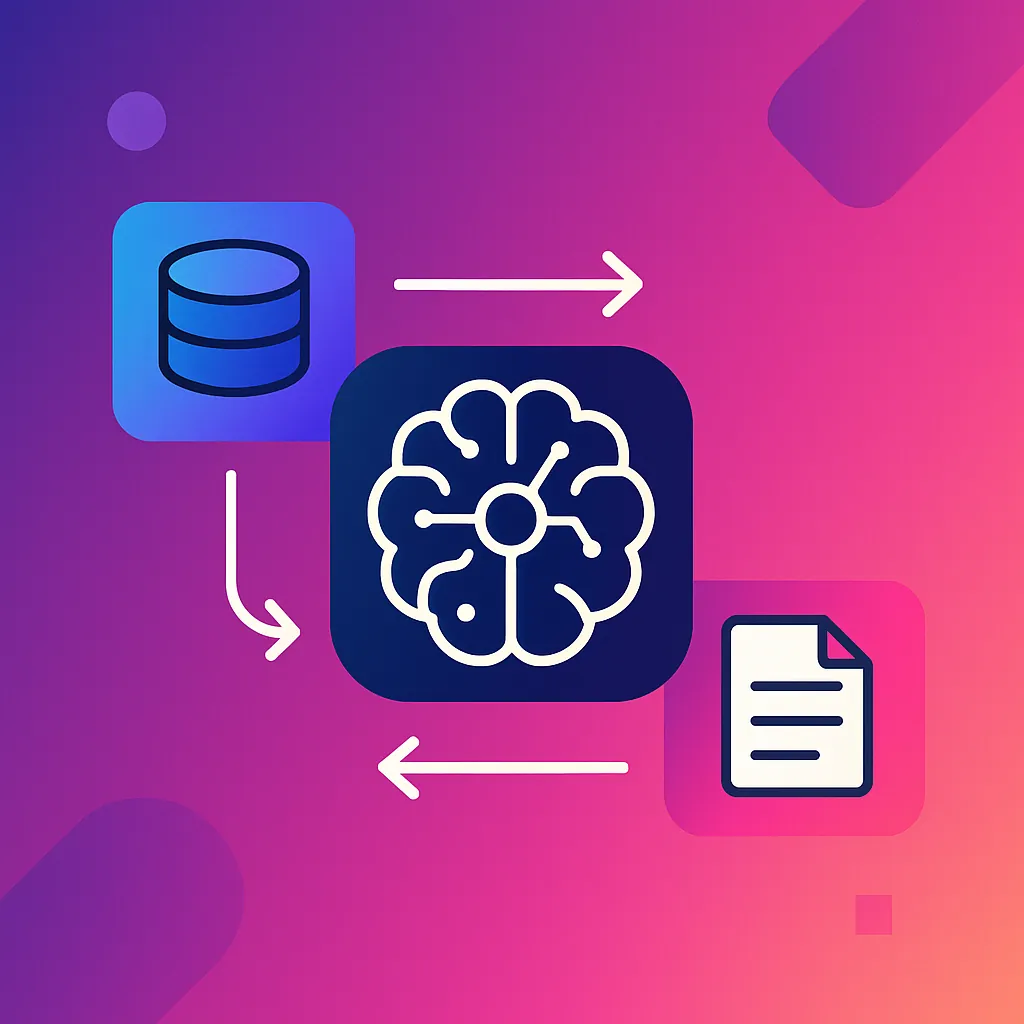
Retrieval-Augmented Generation (RAG) combines a Large Language Model (LLM) with a retrieval system. This way, the LLM doesn't rely solely on its internal parameters but incorporates fresh, specific data before generating its response.
Components of a RAG system
- Document index
- Can be a traditional text index or a vector-based index (embeddings) to capture semantics.
- Retrieval module
- Queries the index with the user's question and returns the most relevant snippets.
- LLM (Generation)
- A model like OpenAI GPT, Mistral, or an open model (LLaMA, Falcon) processes the question along with the retrieved snippets.
- Orchestration
- Controls the flow: receives the question, retrieves data, constructs the prompt, and sends the request to the LLM.
What does RAG bring to an LLM?
- Accuracy: real data mitigate the risk of LLM "hallucinations."
- Continuous updates: updating the index reflects changes without retraining the model.
- Specialization: facilitates adaptation to specific domains (finance, HR, technical support).
Benefits for your business
- More reliable responses in chatbots and virtual assistants.
- Instant report generation based on internal data.
- Operational support: querying manuals, policies, and regulations.
- Decision-making: quick analysis of metrics and trends.
Key use cases
- Customer support: an LLM enriched with internal FAQs and technical documentation.
- Financial reporting: automatic generation of quarterly summaries.
- HR assistant: answers to questions about benefits, onboarding, and policies.
- Sales enablement: creation of personalized proposals based on customer profiles.
By combining retrieval and generation, RAG boosts the performance of LLMs, moving AI from the lab to everyday operations.
— The Digital Motus Team